原创:奇绩创坛

正文
从 ChatGPT 发布到现在已经过去近两年半时间,整个 AI 产业仍在快速发展,认知仍在不断迭代。
在前四篇大模型笔记中,我们对通用智能的内涵本质、延伸机制等作了系统性梳理。到今天,我们愈发清晰地看到,通用智能对科学、技术、生产力,乃至发展模式进行根本性变革的潜力。
把握机会的根本:认清通用智能发展的变与不变
对创业者而言,越是在变革的年代,越是要研究什么是不变的,才能真正分析变化的趋势和方向,顺势而为,找准并把握住新的机会。那么,从奇绩的角度,我们看到了什么不变呢?
不变的是大自然大规模复杂体系的成长方式,以及用来分析技术对人类文明体系发展的影响,和人类本质需求的框架。
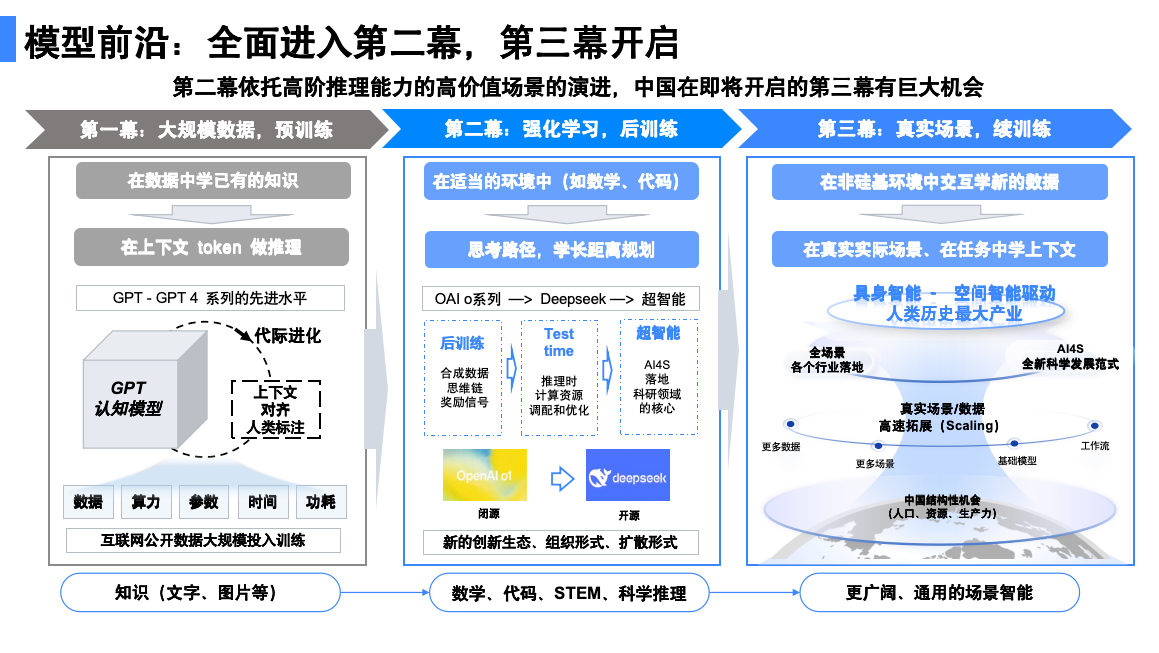
首先,宇宙、生命体和人类社会中的大规模复杂体系,都是通过规模化扩展(Engineering by Scaling)而非工程化构建(Engineering by Construction)而来[1]。本次通用智能的能力也需要采取类似的规模化扩展、数据驱动的方法[2]。
其次,从农业时代、工业时代,再到信息时代、智能时代,技术已不仅是工具,而是人类进化发展的新维度。新的技术会通过技术扩散逐渐推动人类文明体系不断向前发展。
最后,人类的进化是感知、认知、行动三位一体的,即感知信息、进行推理(reasoning),并根据推理结果采取行动。
在上述不变之中,实则蕴含了发展体系内部的诸多变化。当前,我们已经进入通用智能发展的新阶段,无论是技术扩散范式、规模化扩展的方向等模型前沿技术关注焦点,还是模型开发方式等,都与过去呈现出较大不同。
例如,从技术扩散范式的角度看,过去,将新技术应用于产业,通常需要经历从科学发现到技术研发,再到产品开发和商业化的漫长过程。然而,当前,科研、工程化实践、商业化正在 OpenAI、Anthropic 和 DeepSeek 这样的组织中齐头并进,加速推动产业变革。
另外,在模型前沿,关于规模化扩展的探索和实践,当前的焦点也逐渐从预训练 Scaling law,转向 Inference time scaling law 和强化学习扩展(RL scaling)等。同时,在这样的变化中,我们也越来越清晰地看到认知智能、场景智能、具身智能、科学智能这四个快速发展的模型创新方向中蕴含的机会,尤其是 AI 原生生产力机会。
模型前沿的变化:从学知识到学思考
进入新的发展阶段,模型前沿已经发生了较大变化。
过去,模型主要从互联网等数据中学习人类知识,这些知识代表了人类的环境。基于此,模型可以解决简单几步推理的问题。然而,在处理复杂的多步推理(multi-hop reasoning)任务时仍显不足。过去,业界通常使用 LangChain 手动搭建 Agent 框架,并通过 RAG 等方式补充互联网数据中缺乏的上下文(context)。一旦客户、环境或需求发生变化,这类 Agent 应用往往会失效。
而新发展阶段的核心正是通过强化学习,让模型学会思考逻辑,做更长的推理,解决更复杂的问题。和人类似,除了对所处环境建模,模型也开始对思考建模。正如 Inference time scaling law 所显示的,模型思考得越长,天花板可能越高。
最终的模型能力如何,本质上取决于模型的目的或 Agency,即模型的奖励结果。因此,关键在于找到奖励信号(Reward Signal)。只要能够明确奖励信号并有效地收集训练数据,强化学习就能展现出很好的效果。
另外,还可以关注规模化搜索(Scale search),核心是模型能主动搜索更多推理路径,生成样本,评估样本能否构建更长的思维链,反哺到模型预训练中,验证样本是否能够最大化奖励信号并接近最终目标。但需注意,这一认知可能会在未来出现新的变化。
同时,除了学习思考,要进一步提高推理能力,模型还需在交互中学习,学习不同的上下文如何连接。正如人类,厨师炒菜、医生做手术都是在交互中、过程中学习。具身智能领域的研究也正在这一过程中不断发展。尽管模型一部分在物理环境中学习,一部分在仿真环境中学习,但最终仍需要实现从仿真到现实(sim2real)的转化。
模型前沿的关键技术挑战与突破方向
要把握模型前沿焦点从预训练到后训练、强化学习的转变过程中带来的机会,并进一步走向通用智能,需要解决哪些核心问题?
首先,当前的模型还没有较好的持续学习能力。和互联网时代不同,积累的数据越多并不代表模型能力越强。过去,互联网的三个小模型决定了一切:搜索、推荐、广告。这三个模型都形成了数据闭环,用户数据越多,模型效果越好,大家也因此关心流量运营。但目前来看,这一逻辑并不适用于提升大模型能力。现阶段,模型能力的提升需要通过做更多研究,来解决认知的问题。
其次,当前的模型还没有较强的记忆能力。人的记忆分两类,一类是“内挂”,记在大脑里,一类是“外挂”,比如记录在笔记本上。目前模型还无法判断什么内容需要被记忆。谷歌发布了一篇相关论文 Titans [3],但目前文章还没有得到外部验证。
此外,还需解决上下文扩展和跨场景泛化能力。上下文并非简单的 token 长度问题,而是模型需要真正理解什么是重要的,以及如何在模型中体现出来。同时,学习的场景、上下文序列越长,模型能学到得更多,但实现跨不同上下文的学习很难。这可能需要模型架构和模型训练方式的创新。
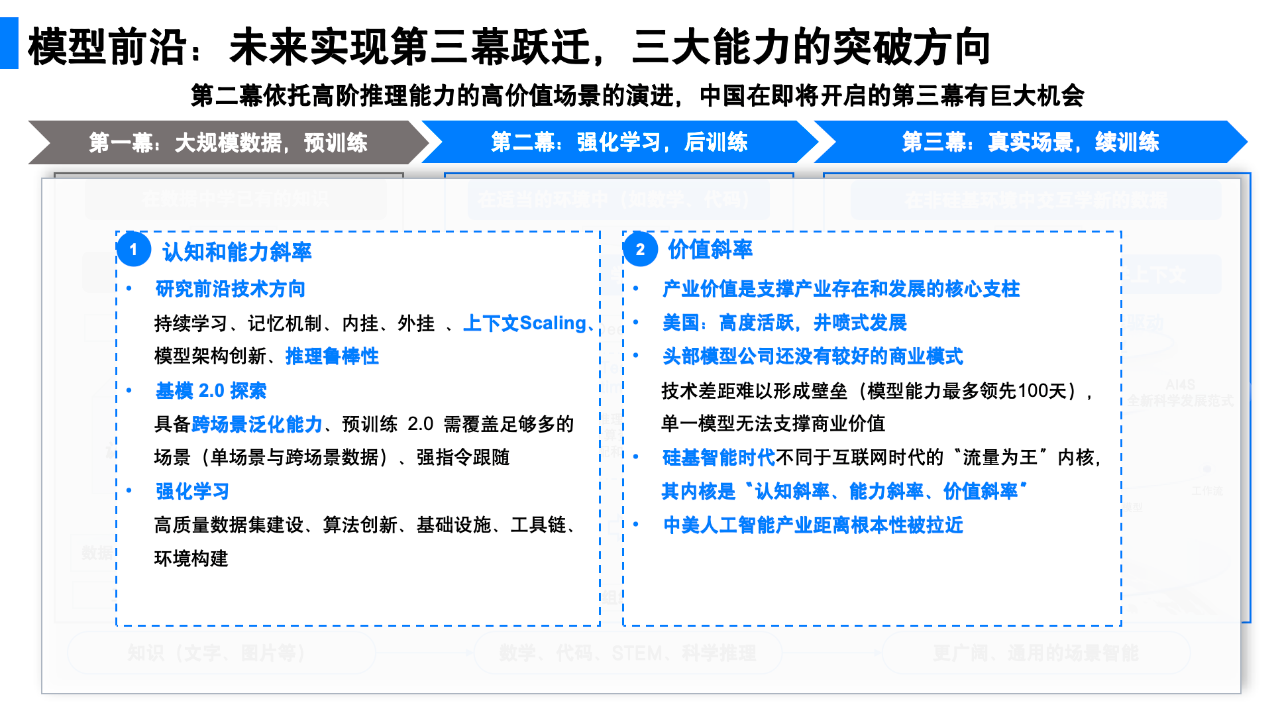
另外,强化学习方面,还存在缺乏外部可用的好的训练框架、高质量数据集,以及基础设施不强、工具链不够等挑战。
比如,在强化学习的训练数据上,当前领域内的领先公司除了关注代码数据,也关注合成大量数学难题及其求解数据,尤其是需要跨代数、几何、微分方程等不同领域的难题。其意义在于让模型学会跨领域思考。由于数学是人造的基于公理的自洽体系,数学领域找到的路径和很多其他领域路径有内在的结构相似性,因此泛化能力较强。但是,除了代码和数学难题之外,目前领域内尚未找到其他合适的训练数据类型。
除了上述挑战,创业者还应关注 DeepSeek 开启的硬件原生的模型架构创新范式。这一趋势在英伟达 CUDA 生态开始有越来越多的领域特定编译语言(DSL)这一现象中也能得到印证。
四个高度活跃的模型创新方向:
认知、场景、具身、科学智能
与模型前沿正在发生的变化相对应,目前有四个模型创新方向正在高速发展。
首先是认知智能,当前以基于语言的强推理模型为核心,沿着这个方向的产品探索主要包括 OpenAI 的 Deep Research ,即将研究产品化。但需关注,如前文所言,模型的奖励是需要解决越来越难的问题而非懂人性。
其次是场景智能,以多模态端到端模型为核心。这类模型只要适当蒸馏,用续训练的方式可以进入医疗、教育、商业服务等各类场景,尤其适合在手机端应用。但需关注的是模型续训练一定要能从场景中,从上下文交互中持续学习。
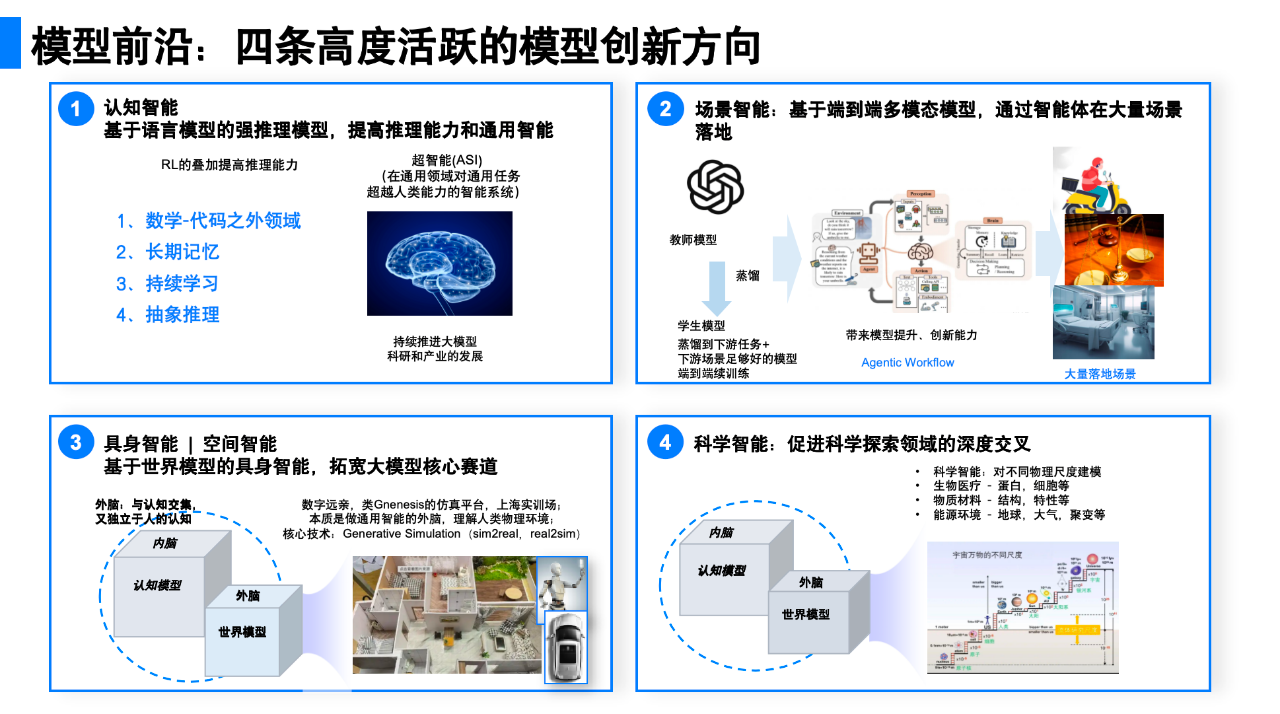
第三个方向是具身智能和空间智能。目前较为活跃的细分领域主要包括机器人大脑、小脑,以及仿真等。另外,还包括李飞飞等团队正在研究的空间智能,即对人的物理空间建模。尽管该方向目前还在发展早期,但长期发展潜能较大。
第四个方向是科学智能或 AI4S。得益于国家推动,目前该方向进展较快,应用领域覆盖生物医疗、物质材料、能源环境等。需关注的探索方向之一是跨尺度建模——采用类似大语言模型的序列建模方法,对物理环境在不同尺度、不同颗粒度建模。模型训练也遵循从预训练到后训练的范式。此外,科学智能与认知智能的结合也值得创业者探究,相关应用如求解动力学方程、薛定谔方程等科学问题。
另外,由于自然数据的缺乏,这四个方向模型能力的提升都离不开合成数据的支持。合成数据的本质是结合人类的先验知识,利用现有模型的能力,来产生数据或增强数据。
这一过程可以类比为“编写教材”,正如人类通过编纂教材将知识体系化地传递给下一代。过去的教材以 SFT(监督式学习,Supervised Learning)为主,正如老师通常会为学生详细地讲解知识点,提供明确的答案和步骤。而当前基于强化学习的合成数据应用,更像是一种少林寺高僧的教学方法——在教授武术动作时,高僧可能只会在徒弟做错动作的时候指出错误,让徒弟自己琢磨正确的动作要领、发力方式等,通过反复的尝试和思考来掌握技能。
面对上述新的变化和新的格局,创业者要抓住这四个方向的发展机会,核心在于明确要解决的关键问题,在不变的框架下找准自己的定位,选择一个能够发挥自身优势的专业领域进行深耕。
同时,创业者需要保持足够陡峭的认知斜率、能力斜率和价值斜率。认知斜率即单位时间内能够进行的研究和思考的深度与广度,以及认知更新的速度;能力斜率要求团队具备强大的基础设施支持,以实现高密度的研究和开发;价值斜率则是指创业者满足市场需求并能够创造与捕获价值的能力。从海外领先企业实践,也不难看出,OpenAI、Anthropic 等在注重提升认知、能力斜率的同时,也正加速产品研发与市场化进程。